March 22, 2019
Machine learning in healthcare parte 2
Malaria
Las imagenes las pueden descargar de este link.
Link para ver la libreta con el código
La malaria es una enfermedad que provoca fiebre, escalofríos y anemia. Esta enfermedad se transmite por la picadura de mosquitos infectados, los parásitos viajan por la sangre hasta el hígado, aquí maduran y producen mas parásitos que infectan a los globulos rojos. Los primeros sintomas se pueden presentar de 10 días a 4 semanas.
Esta enfermedad es común en países tropicales y cada año mueren 1 millón de personas a causa de esta enfermedad.
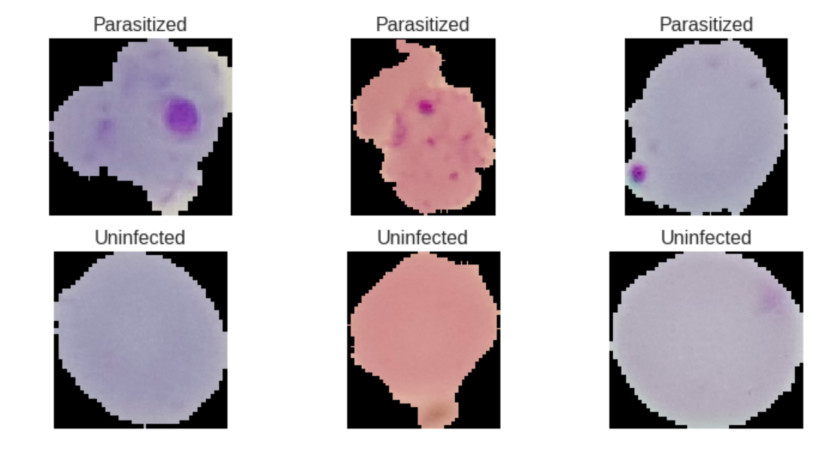
La forma de detectar esta enfermedad es analizando la sangre con un microscopio, el problema es que una sola persona tiene que analizar muchas células rojas de la sangre y detectar si la célula esta infectada, esta tarea es perfecta para una red neuronal convolucional ya que puede detectar las celular infectadas mucho más rapido.
Las imagenes se obtuvieron de 200 pacientes, en total son 27,558 imagenes de celulas de las cuales la mitad son celulas infectadas y la otra mitad son celulas sin infectar. Como tenemos dos clases con el mismo numero de imagenes el entrenamiento de la red neuronal es más sencillo.
Un dato curioso es que estas imagenes se obtuvieron con la camara de un celular pegado a un microscopio. Aquí hay un ejemplo de como se ven las imagenes:
Mobile net
El modelo que utilicé fue MobileNet v2 en keras, elegí este modelo ya que esta hecho para que funcione correctamente en dispositivos moviles como un celular.
Mobile net en lugar de usar capas convolucionales usa unas capas llamadas depthwise separable convolutions que se dividen en dos operaciones depthwise convolution y pointwise convolution. Como recordamos una capa convolucional normal usa kernels o filtros que pasan por toda la imagen para extraer información, si tenemos una imagen de tamaño 10x10x3 y 1 kernel 3x3x3 el resultado sera una imagen de tamaño 8x8x1, como podemos observar la primera imagen tiene una profundidad de 3 que indica los colores de la imagen (RGB) y el kernel también necesita una profundidad de 3 para cada canal de color y es como si tuvieramos 3 kernels de 3x3, al final estos tres kernels se combinan para obtener la imagen resultante de tamaño 8x8x1 con profundidad 1. En una capa solemos tener varios kernels por ejemplo 128, si la imagen es a color con una profundidad de 3 es como si tuvieramos 128x3 kernels en total pero la imagen resultante tendria un tamaño de 8x8x128 ya que como acabamos de ver los kernels para cada canal de color se combinan.
En las capas depthwise separable convolutions la primera operación que se realiza es depthwise convolution y el resultado de esta operación es una imagen con profundidad de 3 (8x8x3) ya que la capa aplica los kernels a cada canal de color por separado, despues esta imagen (8x8x3) pasa por la siguiente operación pointwise convolution, esta operación usa un kernel de tamaño 1x1x3 para que la imagen resultante tenga el mismo tamaño (8x8) pero en este caso tenga un solo canal de color 8x8x1, si queremos la misma profundidad que en la capa convolucional normal entonces podemos crear 128 kernels de 1x1x3 para obtener una imagen de tamaño 8x8x128.
En resumen las capas depthwise separable convolutions dividen el trabajo de una capa convolucional normal en dos. Aunque al principio esto no parezca una buena idea el resultado demuestra lo contrario, en la capa convolucional normal del primer ejemplo tenemos 128 kernels de tamaño 3x3x3 que se movera 8x8 posiciones en la imagen 10x10x3 si multiplicamos esto:
128x3x3x3x8x8 = 221,184
En total se realizan 221,184 multiplicaciones en esta capa convolucional normal, si usamos una capa depthwise separable convolution recordemos que en la primera operación tenemos 3 kernels de tamaño 3x3x1 para cada canal de color de la imagen y estos kernels se mueven 8x8 posiciones:
3x3x3x1x8x8 = 1,728
en la segunda operación tenemos 128 kernels de tamaño 1x1x3 que se mueven 8x8x posiciones:
128x1x1x3x8x8 = 24,576
En total se realizan 1,728 + 24,576 (26,304) multiplicaciones en esta capa, una capa convolucional normal realiza 8 veces más estas multiplicaciones, es por eso que dividir el trabajo en dos tareas resulta mejor.
Modelo
MobileNet v2 esta entrenado con el set de datos ImageNet y los pesos estan disponibles para que los puedas usar, esto se llama transfer learning y evita que tengas que entrenar un modelo desde cero pero para entrenar este modelo usé pesos aleatorios lo cual me dío un buen resultado.
Usé un learning rate de 3e-4 (0.0003) y su valor se va reduciendo cada vez que los ciclos de entrenamiento (epochs) aumetan gracias a la función LearningRateScheduler de Keras, el batch size fue de 32 y las imagenes tenían un tamaño de 96x96x3.
Fueron 30 ciclos de entrenamiento epochs y fue en el ciclo 24 donde el modelo alcanzo la maxima exactitud en el set de validación con 96.4%.
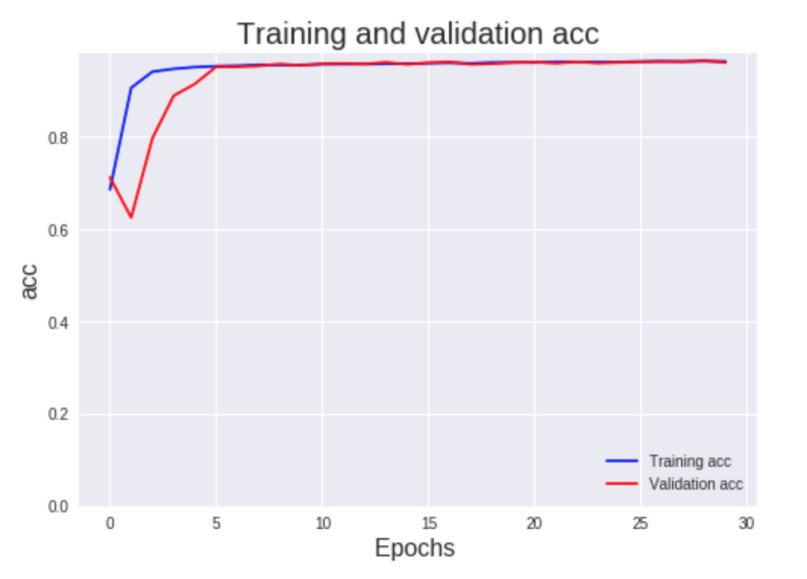
El optimizador que usé fue Stochastic gradient descent (SGD) con un momentum de 0.9, (SGD) funciona muy bien como optimizador, en este caso funciono mejor que Adam aunque el entrenamiento fue un poco más lento.
Como ya mencione en un post anterior en este tipo de problemas es bueno usar otro tipo de metricas como la sensibilidad y la especificidad. La matriz de confusión es la siguiente:
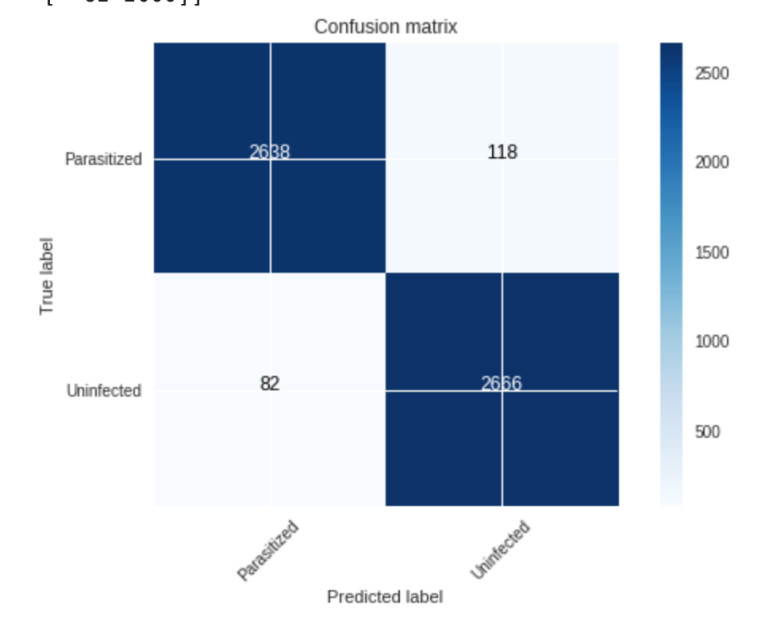
La sensibilidad es de 95.8% y la especificidad es del 97%.
Recordemos que si un modelo tiene una alta sensibilidad y el modelo predice un resultado negativo podemos estar seguros que la celula no esta infectada y si el modelo tiene una alta especificidad y el modelo predice un resultado positivo podemos estar seguros de que la celula esta infectada.
Entrenar el modelo y organizar los datos no me tomo mucho tiempo, lo más importante fue la calidad de los datos, si son buenas imagenes y si la cantidad es suficiente se puede crear un modelo potente en poco tiempo, el siguiente paso es adaptar el modelo para que funcione en un celular, con esto tendriamos una poderosa herramienta en el bolsillo.
Breast cancer
Las imagenes las pueden descargar de kaggle.
Link para ver la libreta con el código
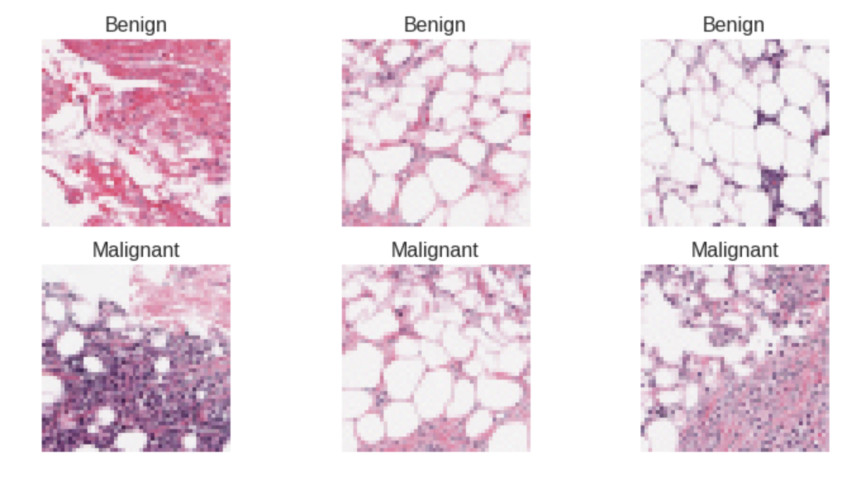
El cáncer de mama es el cáncer más común entre las mujeres, en estas imagenes encontramos el cancer carcinoma ductal invasivo.
Este set de datos se compone de 277,524 imagenes de tamaño 50x50 que fueron extraidas de imagenes más grandes, cada una de estas imagenes indica si el tumor es maligno o benigno. Los tumores malignos son aquellos que se pueden expandir a otros tejidos y los tumores benignos son tumores que no invade a otros tejidos y presentan un crecimiento lento.
Algunas tecnicas para detectar el cáncer provocan que el tumor se expanda más rapido y que afecte a las areas cercanas.
Una tecnica segura es tomar tejido de una biopsia y analizarla.
Tenemos 198,738 imagenes de tumores benignos y 78,786 imagenes de tumores malignos, en este caso no tenemos clases balanceadas, hay casi el doble de imagenes de la clase benigno.
En este problema usé de nuevo el modelo Mobile net v2 con pesos aleatorios y el parametro alpha con valor de 1.5 para que el modelo tuviera más capas (layers)
El valor del learning rate fue de 3e-4 y se va reduciendo mientras pasan los ciclos (epochs), el batch size fue de 128 en 20 ciclos.

Usé SGD como optimizador con un momentum de 0.9
La exactitud en el set de validación fue de 86.8% y la exactitud en el set de entrenamiento fue de 85.2%

La sensibilidad fue de 85.6% y la especificidad fue de 86%. Para lograr esto use pesos para cada clase, le dí mas importancia a la clase Malignant ya que tiene menos imagenes.