Nov. 9, 2018
Dropout y Batch Normalization
Antes de entrar en el mundo de las redes neuronales convolucionales tenemos que ver dos metodos muy importantes que ayudan a las redes neuronales en el proceso de entrenamiento. Son metodos diferentes pero se apoyan entre si.
Dropout
Dropout es un metodo que desactiva un numero de neuronas de una red neuronal de forma aleatoria. En cada iteración de la red neuronal dropout desactivara diferentes neuronas, las neuronas desactivadas no se toman en cuenta para el forwardpropagation ni para el backwardpropagation lo que obliga a las neuronas cercanas a no depender tanto de las neuronas desactivadas. Este metodo ayuda a reducir el overfitting ya que las neuronas cercanas suelen aprender patrones que se relacionan y estas relaciones pueden llegar a formar un patron muy especifico con los datos de entrenamiento, con dropout esta dependencia entre neuronas es menor en toda la red neuronal, de esta manera la neuronas necesitan trabajar mejor de forma solitaria y no depender tanto de las relaciones con las neuronas vecinas.
Dropout tiene un parametro que indica la probabilidad de que las neuronas se queden activadas, este paremetro toma valores de 0 a 1, 0.5 suele usarse por defecto indicando que la mitad de las neuronas se quedaran activadas, si los valores son cercanos a 0 dropout desactivara menos neuronas, si es cercano a 1 desactivara muchas más neuronas. Dropout solo se usa durante la fase de entrenamiento, en la fase de pruebas ninguna neurona se desactiva pero las escalamos on la probabilidad del dropout para compensar a las neuronas desactivadas durante la fase de entrenamiento.
Se puede establecer un dropout diferente por cada capa, dependiendo de lo que necesitemos en cada una, en las capas de entrada suele usarse un dropout muy alto (0.7) para mantener a la mayoria de neuronas activadas y en capas ocultas un dropout de (0.5).
En articulos que hablen sobre dropout y en la explicación oficial el parametro del metodo sirve para establecer el porcentaje de neuronas que se mantendran activadas tal y como lo explique pero en keras este parametro funciona de manera contraría, aquí indica el porcentaje de neuronas que se desactivaran en la red neuronal, si en teoria teniamos que el parametro del dropout de 0.7 es para mantener a la mayor parte de las neuronas activadas en keras tendriamos que poner un parametro de 0.3 para indicar lo mismo.
Si queremos usar dropout con keras la sintaxis es la siguiente:
model = Sequential()
model.add(Dropout(0.3, input_shape=(12288,)))
model.add(Dense(units=16))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(units=32))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(units=64))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(units=3, activation="softmax"))
Como notamos dropout no se usa en la capa de salida ya que en esta capa es necesario que siempre esten activas todas las neuronas.
Si queremos usar dropout en la capa de entrada:
second_model.add(Dropout(0.3, input_shape=(12288,)))
En las capas ocultas, la
capa dropout tiene que ir despues de la capa de activación:
model.add(Dense(units=16))
model.add(Activation('relu'))
model.add(Dropout(0.5))
En la fase de pruebas keras se encargara de desactivar dropout por lo cual no tenemos que preocuparnos por nada, solo por encontrar buenos hiperparametros para cada capa.
Algunos consejos para implementar dropout:
-
Como dropout desactiva un porcentaje de neuronas, es necesario aumentar las capas de una red neuronal para evitar underfitting.
-
El valor del parametro learning rate puede ser más grande que en una red neruronal sin dropout.
Batch normalization
Batch normalization es un metodo que normaliza cada lote de datos (bath_size), como vimos en el tutorial de keras es necesario que los datos se normalicen para evitar que se tengan distancias muy diferentes entre ellos como en una imagen a color que se pueden tener valores de 0 hasta 255. Normalizando los datos las distancias de los datos van de 0 a 1 y esto ayuda a la red neuronal a trabajar mejor y a tener menos problemas, pero cuando normalizamos los datos solo la capa de entrada se beneficia de esto, conforme los datos pasan por otras capas ocultas esta normalización se va perdiendo y si tenemos una red neuronal con muchas capas podemos tener problemas con el entrenamiento. El metodo de batch normalization normaliza los datos antes de que pasen por la función de activación en cada capa que de la red neuronal, de esta manera siempre tendremos los datos normalizados.
Este metodo tambien resuelve un problema llamado covariate shift, si queremos entrenar a una red neuronal necesitamos una buena cantidad de datos, en la red neuronal que construimos teniamos imagenes de modelos de tesla, cuando la red neuronal esta en la fase de entrenamiento recordemos que dividimos los datos de entrenamiento en lotes más pequeños (bath size), si las imagenes de los coches tienen distrubuciones diferentes por ejemplo una cierta cantidad de imagenes son tesla de color rojo y otra cantidad son tesla de color azul es necesario que cada lote contenga imagenes de ambas distribuciones, imagenes de tesla de color azul y tesla de color rojo, si un lote solo contiene imagenes de un solo color de tesla el entrenamiento sera más lento y tendremos que elegir hiperparametros con más cuidado como el learning rate, este problema puede solucionarse si mezclamos los datos aleatoriamente pero esto solo ayuda a la capa de entrada, en las capas ocultas la distribución de cada neurona cambia en la fase de entrenamiento, lo que buscamos es tener una distribución fija en cada neurona.
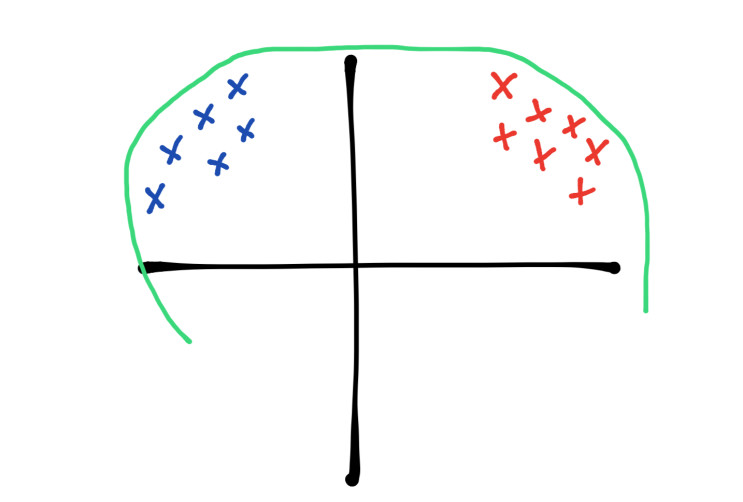
En la imagen supongamos que los puntos azules son las imagenes de teslas color azul y los puntos rojos son imagenes de teslas de color rojo, la linea verde es la línea de decisión, como podemos notar las imagenes tienen una distribución diferente y estan lejos una de otra, por esta razón la red neuronal tarda más en realizar el proceso de entrenamiento ya que tiene que buscar una linea de decisión más compleja que contenga a todos los datos.
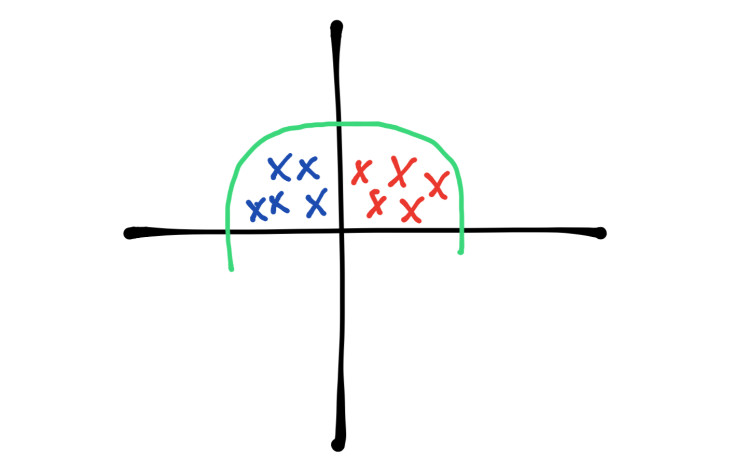
Si normalizamos los datos las distribuciones ahora estan más cerca y es más facil para la red neuronal crear una línea de decisión, como mencione esto se puede lograr normalizando los datos de entrada pero para que tengamos este comportamiento en las capas ocultas necesitamos usar el metodo batch normalization.
batch normalization implementa dos nuevos parametros que se actualizan con el backpropagation, estos parametros sustituyen al parametro b.
En keras podemos implementar este metodo como una capa que se ubica antes de la función de activación:
model = Sequential()
model.add(Dense(units=16, input_shape=(12288,), use_bias=False))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dense(units=32, use_bias=False))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dense(units=64, use_bias=False))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dense(units=3, activation="softmax"))
Es importante especificar use_bias=False.
Las ventajas de usar batch normalization son parecidas a las ventajas de usar dropout, se pueden usar ambos metodos al mismo tiempo, aunque lo recomendable es usar primero batch normalization y despues, si se necesita, usar dropout.