Jan. 28, 2019
Conceptos importantes en Machine Learning
Correlación y Causalidad
Estos dos terminos suelen confundirse pero la explicación es muy sencilla, existe una correlación cuando dos variables tienen una relación entre sus valores, si aumenta el valor de una variable la otra también aumenta o disminuye, si ponemos un ejemplo popular, en Nueva York el precio de una rebanada de pizza aumenta o disminuye junto con el precio del metro, existe una correlación entre estas dos variables pero esto no implica que una afecte (o cause) a la otra variable, no existe una causalidad entre las dos variables, lo que causa la causalidad es la inflación, la inflación obliga a que ambos precios suban o bajen. Correlación no implica causalidad.
Verdadero (Positivo, Negativo) Falso (Positivo, Negativo)
-
Verdadero Positivo (VP): Es el resultado cuando el modelo predice correctamente la clase Positiva.
-
Verdadero Negativo (VN): Es el resultado cuando el modelo predice correctamente la clase Negativa.
-
Falso Positivo (FP): Es el resultado cuando el modelo predice incorrectamente la clase Positiva.
-
Falso Negativo (FN): Es el resultado cuando el modelo predice incorrectamente la clase Negativa.
Un truco para recordar esta tabla es que siempre el concepto de la derecha (Positivo, Negativo) es lo que el modelo predice y el concepto de la izquierda (Verdadero, Falso) menciona si el modelo se equivoco o no.
Exactitud (Accuracy)
Conociendo los conceptos anteriores podemos definir la exactitud como lo siguiente:
Exactitud = Numero de predicciones correctas / numero total de predicciones
Exactitud = VP + VN / FP + FN + VP + VN
Precisión y Exhaustividad (Precision and Recall)
Existen set de datos donde las clases no estan balanceadas correctamente y podemos tener más datos de una clase T y menos datos de una clase H, cuando tenemos este tipo de problemas la exactitud (Accuracy) no nos sirve para evaluar el modelo, un ejemplo común es cuando tenemos datos sobre un tumor, el tumor puede ser benigno (No canceroso / clase negativa) o maligno (Canceroso / clase positiva), generamente tenemos más datos de la clase negativa (benigno) que de la clase positiva (maligno), si tenemos:
91 datos de la clase negativa (benigno) y 9 datos de la clase positiva (maligno) podriamos tener un modelo que siempre clasifique con la clase negativa:
Verdadero Positivo (VP): 0
Verdadero Negativo (VN): 91
Falso Positivo (FP): 0
Falso Negativo (FP): 9
y usando la formula de la exactitud:
Exactitud = 0 + 91 / 0 + 9 + 0 + 91
Exactitud = 91 / 100 = 0.91
Tendriamos un 91% de exactitud en un modelo que lo unico que hace es clasificar todos los datos como negativos, para resolver este problema podemos usar otros metodos para evaluar el modelo:
Precisión (Precision)
La precisión indica que porcentaje de los datos clasificados como positivos es correcto (Que porcentaje de los tumores marcados como malignos son realmente malignos):
Precisión = VP / VP + FP
Si la precisión es 1 esto quiere decir que el modelo no produce Falsos Positivos
Si usamos esta metrica para evaluar un modelo con las siguientes predicciones:
VP = 1
VN = 90
FP = 1
FN = 8
9 datos de tumores malignos (clase positiva), 91 datos de tumores benignos (clase negativa)
Precisión = 1 / 1 + 1
Obtenemos una precisión de 0.5 esto quiere decir que de todos los tumores que clasificamos como malignos solo el 50% de ellos son realmente malignos, recordemos que clasificamos dos tumores como positivos (VP = 1, FP = 1) uno lo clasificamos correctamente (VP = 1) y el otro fue incorrecto (FP = 1).
Exhaustividad (Recall)
La exhaustividad indica que porcentaje de datos positivos reales se clasificaron correctamente (Que porcentaje de los tumores que sabemos que son malignos fueron marcados como malignos)
Exhaustividad = VP / VP + FN
Si la exhaustividad es 1 esto quiere decir que el modelo no produce Falsos Negativos
Exhaustividad = 1 / 1 + 8
Obtenemos una exhaustividad de 0.11, de los datos que tenemos de tumores malignos solo clasificamos correctamente el 11% de esos datos, tenemos 9 datos de tumores malignos y solo clasificamos 1 de esos datos como maligno.
En algunos modelos podemos establecer un punto llamado Threshold (en español podemos traducirlo como umbral), en el caso de las redes neuronales sabemos que la capa de salida da un puntaje a cada dato para indicar a que clase pertenece, si tenemos una clasificación binaria usamos la función sigmoid que arroja un valor entre 0 y 1 para indicar la clase, aqui podemos establer el Threshold en 0.5, si la función sigmoid arroja un valor menor a 0.5 el dato pertenece a la primera clase, si la función arroja un valor igual o mayor a 0.5 el dato pertenece a la segunda clase, si el valor esta mas cerca de 1 indica que la red neuronal esta más segura que ese dato pertenece a la clase 2, entonces si queremos una red neuronal más robusta podemos establecer un Threshold mayor, por ejemplo un 0.7, esto provoca que cambie el resultado de precisión y de exhaustividad.
Si aumentamos el Threshold:
El numero de falsos positivos disminuye y los falsos negativos aumentan, la precisión aumenta y la exhaustividad disminuye.
si disminuimos el Threshold:
El numero de falsos positivos aumenta y los falsos negativos disminuyen, a precisión disminuye y aumenta la exhaustividad.
Si queremos tener un buen modelo basado en la precisión y la exhaustividad tenemos que medir ambos valores por igual y buscar que sean valores parecidos.
Curva ROC
La curva ROC (curva de característica operativa del recepto) es un grafico que muestra el rendimiento de un modelo en todos los puntos Threshold. Esta curva muestra dos parametros:
Tasa de verdaderos positivos (TPR) = VP / VP + FN (Podemos notar que es la misma formula de la Exhaustividad)
Tasa de falsos positivos (FPR) = FP / FP + VN
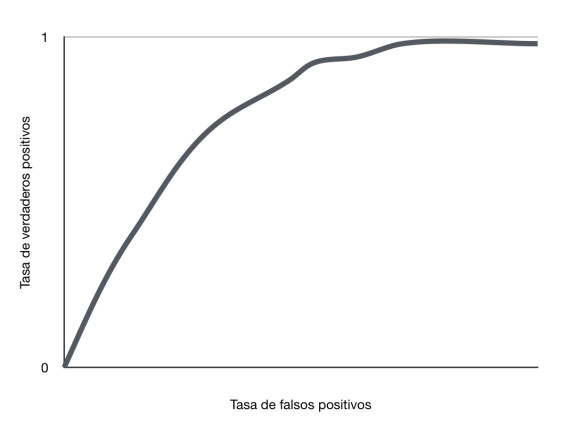
Siempre queremos que la curva este lo mas cerca posible al area de verdaderos positivos, esto indica que clasifica la mayoria de datos correctamente.
Si disminuimos el Threshold el modelo clasificara más datos como positivos, esto aumenta los falsos positivos y los verdaderos positivos.
AUC: Área bajo la curva ROC
Gracias a AUC podemos evaluar el rendimiento del modelo usando la curva ROC.
En la siguiente imagen:
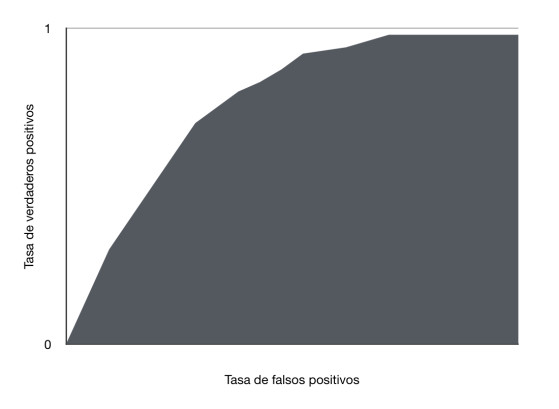
Podemos notar que esta curva ROC tiene un area (AUC) entre 0.5 y 1, conforme la curva se acerque al area de verdaderos positivos el area bajo la curva aumentara, si obtenemos un area de 1 tendriamos un modelo que clasifica los datos perfectamente pero hay que tener cuidado con esto ya que puede indicar sobre ajuste (overfitting).
Una forma de explicar el AUC es como la probabilidad de que el modelo clasifique un ejemplo positivo aleatorio más alto que un ejemplo negativo aleatorio, en otras palabras la probabilidad de que el modelo otorgue una puntuación alta a un ejemplo positivo aleatorio (para indicar que pertecene a la clase positiva) y una puntuación baja a un ejemplo negativo aleatorio (para indicar que el ejemplo pertenece a la clase negativa). El AUC de la imagen anterior (que es un area entre 0.5 y 1) indica que el modelo clasifica un ejemplo positivo aleatorio mas alto que un ejemplo negativo aleatorio el 50% de las veces.
AUC es invariable al threshold, siempre tiene en cuenta la calidad de las predicciones del modelo, este comportamiento no siempre es bueno, por ejemplo si tenemos un problema donde hay que clasificar correos spam podriamos preferir tener menos falsos positivos aunque esto aumente los falsos negativos, en otras palabras preferimos tener una metrica donde el modelo no marque correos importantes como spam, aunque esto aumente los correos spam que se marcan como correos normales, todo depende del problema que quieras resolver y como lo quieres resolver.
Bias-variance Trade Off
Podemos definir bias y variance como lo siguiente:
-
Bias: Error que existe en el set de datos de entrenamiento
-
Variance: Error que existe en el set de datos de validación
Pongamos cuatro ejemplos:
-
Tenemos 1% de margen de error en el set de entrenamiento y 15% de margen de error en el set de validación, en este caso tenemos high variance ya que el modelo tiene un mal desempeño con el set de validación (Overfitting).
-
Tenemos un 15% de margen de error en el set de entrenamiento y un 17% de margen de error en el set de validación, en este caso tenemos high bias ya que el modelo tiene un mal desempeño en el set de entrenamiento (Underfitting).
-
Tenemos un 15% de margen de error en el set de entrenamiento y un 30% de margen de error en el set de validación, en este caso tenemos high variance porque el desempeño con los datos de entrenamiento es pobre y también tenemos high bias ya que el desempeño en los datos de validación esta lejos del desempeño en los datos de entrenamiento.
-
Tenemos 0.6% de margen de error en el set de entrenamiento y un 1% de error en el set de validación, aqui tenemos low bias ya que tenemos un buen desempeño en los datos de entrenamiento y también tenemos low variance ya que el desempeño en los datos de validación es igual de bueno.
Regularización
Sabemos que la regularización sirve para evitar el overfitting, existen dos algoritmos que penalizan la complejidad de un modelo para evitar el overfitting, estos dos algoritmos se agregan a la función de perdida.
L2 (Ridge)
La formula de este aloritmo de regularización es la siguiente:
L2 = |W ^ 2|
Los || sirven para obtener el valor absoluto, esto significa que si hay un peso negativo por ejemplo -5 usando || obtenemos el numero positivo 5, de esta manera puede contribuir a la función de perdida, si lo dejaramos en negativo este peso restaría valor a la función de perdida y no serviría para regularizar al modelo.
La suma de todos los pesos (W) al cuadrado del modelo, en esta formula si W tiene un valor muy grande afecta más a la complejidad del modelo y es penalizado, si W tiene un valor cercano a 0 afecta muy poco a la complejidad del modelo y no es penalizado, recordemos que esta formula se suma a la función de perdida, cuando la función de perdida se minimiza el gradient descent busca que los valores de W no sean grandes para evitar esta penalización.
A esta formula se le agrega un hyperparametro llamado lambda ?, este hyperparametro multiplica al algoritmo de regularización, entre más grande sea el valor de lambda el efecto de regularización es mayor lo cual puede provocar un modelo muy simple con underfitting. Al final este es un hyperparametro al cual le tenemos que buscar un valor acorde al problema que tenemos.
L1 (LASSO)
Como vimos el algoritmo L2 forza a que los pesos W sean cercanos a 0, el algoritmo L1 los deja exactamente en 0.
L1 = |W|
La suma de los valores absolutos de W.
L1 busca los features que no ayudan a mejorar el modelo y deja sus pesos W en 0 para que no afecten al modelo, en otras palabras L1 reduce el numero de features de un modelo.
Mínimos cuadrados ordinarios
Es el metodo que usan los modelos de regresión lineal para encontrar los parametros b y W, este metodo busca minimizar la suma de las diferencias entre los puntos de los datos de la muestra y los puntos que el modelo predijo al cuadrado.
Collinearity
Colinealidad es un problema de los modelos de regresión lineal, sucede cuando dos variables independientes estas correlacionadas entre si y esto afecta al metodo de mínimos cuadrados ordinarios (ordinary least squares).
Multicollinearity
La multicolinealidad sucede cuando una variable independiente esta correlacionada con otras variables independientes, este problema al igual que la colinealidad afecta al metodo de mínimos cuadrados ordinarios, lo que se tendria que hacer es eliminar las variables independientes que esten correlacionadas y solo usar la más importante. Cuando tenemos este tipo de problema podemos usar Ridge Regression o Lasso Regression. Ridge Regression es el modelo de regresión lineal con el algoritmo de regularización L2, Lasso Regression es el modelo de regresión lineal con el algoritmo de regularización L1, como recordamos L1 deja los pesos W de las features menos importantes en 0 para que no se tomen en cuenta a la hora de entrenar el modelo, esto puede ser util para eliminar los features que provocan la multicolinealidad.
Curse of Dimensionality
Esto ocurre cuando tenemos una gran cantidad de features en un data set, esto significa que tenemos muchas dimensiones en los datos que aumentan su complejidad, necesitamos más instancias en cada dimensión (o feature) para representarlos correctamente en un modelo, existen ocasiones donde tenemos más dimensiones que instancias en los datos y tenemos que aplicar tecnicas para remover algunas dimensiones.
Dimensionality Reduction
Como su nombre lo indica podemos reducir las dimensiones de un set de datos esto ayuda a evitar Curse of Dimensionality y la multicolinealidad. Existen dos metodos para lograr esto: Feature Selection y Feature Extraction.
Feature Selection
En este metodo seleccionamos los features que sean mejores para el modelo, podemos usar dos tecnicas Backward Feature Elimination y Forward Feature Selection
Feature Extraction
En este metodo transformamos los datos a features que sean mejor para el modelo. Un algoritmo popular para lograr esto se llama PCA (Principal Component Analysis).
Ensambles
Un ensamble es una serie de modelos que son combinados para realizar mejores predicciones, Random forest es uno de los ensambles más populares, este metodo combina varios arboles de decisión para realizar la predicción, si lo queremos usar para clasificación la clase final del modelo sera la que más se repita entre los arboles de decisión, si lo usamos para regresión el valor final sera la media de los valores de los arboles de decisión.
Los ensambles se pueden crear con dos algoritmos:
-
Bagging:
-
Se enfoca en reducir la varianza y evitar el overfitting para mejorar la exactitud (Accuracy)
-
Bagging otorga la misma importancia a todos los modelos sin importar cual sea mejor o peor.
-
Bagging toma datos aleatoriamente para entrenar cada modelo, gracias a esto los modelos se pueden ejecutar en paralelo.
-
Si se tiene un problema de overfitting es buena idea usar este algoritmo de ensamble.
-
-
Boosting:
-
Se enfoca en reducir el bias, puede convertir modelos con desempeño pobre en modelos con un buen desempeño.
-
Boosting le otorga más importancia a los modelos con mejor desempeño
-
Boosting entrena los modelos secuencialmente para ir mejorando cada modelo dependiendo de la exactitud del modelo anterior, por esta razon no se pueden ejecutar en paralelo.
-
Si se tiene un problema de underfitting es buena idea usar este algoritmo.
-
Random forest es un ensamble basado en Bagging, puede mejorar la exactitud y evitar el overfitting, también puede ser ejecutado en paralelo lo cual lo hace rapido y eficiente.