Nov. 2, 2018
Cómo crear una red neuronal con keras
Keras es un framework para crear redes neuronales, esta construido sobre Tensorflow, otro framework de machine learning. La idea de Keras es ser un framework sencillo de entender, con una sintaxis amigable para el usuario y una herramienta donde puedas crear redes neuronales de manera rapida, por estas razones aprenderemos primero como usar Keras y posteriormente veremos Tensorflow que es más complejo pero que otorga mayor libertad.
En este tutorial crearemos una red neuronal que pueda reconocer los distintos modelos de coches de tesla, model s, model x y model 3, las imágenes las recopile de una busqueda en Google Images.
Un punto muy importante a la hora de crear un modelo son los datos, existen set de datos listos para probar modelos que vienen en frameworks como Keras o scikit-learn y son faciles de importar:
from keras.datasets import cifar10
(X_train, y_train), (X_val, y_val) = cifar10.load_data()
En dos líneas de código tenemos los datos listos para usarlos en el modelo. En la vida real obtener datos funciona de una manera muy diferente, nosotros tenemos que recopilarlos o si tenemos suerte, encontrar un set de datos que podamos usar, pero generalmente los datos son un caos, tienen muchos problemas, valores nulos, valores repetidos, nombres incorrectos y este es uno de los trabajos más importantes, limpiar los datos y explorarlos para mejorarlos, como en este tutorial usaremos imágenes la exploración sera diferente con respecto a tener datos tabulados(datos que vienen en archivos csv que se exploran con pandas).
Empezaremos descargando los datos y seguiremos una serie de pasos para posteriormente dividir las imagenes en el set de validación y el set de entrenamiento.
Obteniendo las imágenes
Recomiendo usar la libreta donde ya esta todo el código y los datos descargados, es importante al menos darle un vistazo ya que es muy probable que los resultados de la red neuronal sean diferentes, más adelante veremos la razón.
Los datos estan en Github en este link.
Importaremos las librerias necesarias aunque para obtener los datos solo necesitaremos unas cuantas:
import numpy as np
import os
import shutil
from keras.preprocessing.image import load_img, img_to_array
from keras.utils import to_categorical
from keras.models import Sequential
from keras.layers import Dense, Activation
from matplotlib import pyplot as plt
from numpy.random import seed
import tensorflow as tf
from keras import backend as k
import os
Es necesario instalar keras para poder trabajar en el tutorial, recomiendo usar Google colab, ya tiene todas las librerías instaladas y tenemos acceso a una computadora potente para crear redes neuronales.
Necesitamos crear las siguientes carpetas, si estas en linux o mac puedes usar el siguiente comando:
!mkdir -p validation_images/tesla_model_3 && mkdir validation_images/tesla_model_s && mkdir validation_images/tesla_model_x
También puedes crearlos en el explorador de archivos.
Con las siguientes líneas de código pasaremos 30 imágenes del set de datos de entrenamiento al set de datos de validación
validation_set_size = 30
def move_images(from_path, to_path):
files = os.listdir(from_path)
folder_size = len(files)
first_index = folder_size - validation_set_size
files_to_move = files[first_index:]
for file_name in files_to_move:
source_file_name = from_path + file_name
destination_file_name = to_path + file_name
shutil.move(source_file_name, destination_file_name)
Usamos la librería shutil que permite controlar archivos por medio de python y la librería os para explorar las carpetas y obtener los nombres de las imágenes.
move_images("./tesla-cars-dataset-master/tesla-model-3/", "./validation_images/tesla_model_3/")
move_images("./tesla-cars-dataset-master/tesla-model-s/", "./validation_images/tesla_model_s/")
move_images("./tesla-cars-dataset-master/tesla-model-x/", "./validation_images/tesla_model_x/")
Ejecutamos la función indicando las rutas donde se encuentran las carpetas.
Todo el manejo de archivos, ya sea mover carpetas, renombrarlas o eliminarlas se puede realizar con el explorador de archivos de cada sistema operativo pero es importante conocer los comandos de linux y las herramientas de python para este tipo de tareas, de esta manera se pueden automatizar. Generalmente cuando se trabaje en un proyecto grande se necesitaran usar servidores en la nube y la manera más rapida de manejar archivos en estos servidores es con comandos.
Renombramos las carpetas del set de entrenamiento para que coincidan mejor con los nombres del set de validación
!mv tesla-cars-dataset-master training_images
!mv training_images/tesla-model-3 training_images/tesla_model_3
!mv training_images/tesla-model-s training_images/tesla_model_s
!mv training_images/tesla-model-x training_images/tesla_model_x
Cargando las imágenes
Ya que tenemos las imágenes divididas en carpetas ahora toca cargarlas en variables de python para posteriormente usarlas con la red neuronal:
img_height = 64
img_width = 64
def load_images(paths):
X = []
y = []
for path in paths:
images_paths = os.listdir(path)
for image_path in images_paths:
complete_path = path + image_path
image = load_img(complete_path, target_size=(img_height, img_width))
image_array = img_to_array(image)
X.append(image_array)
label = paths.index(path)
y.append(label)
return X, y
Estamos usando dos funciones de keras, load_img permite cargar un archivo de imagen y modificar su tamaño, queremos que la imagen sea 64 * 64, img_ to_array convierte cada imagen en un array. Recordemos que una imagen a color tiene valores de 0 a 255 indicando que tan fuerte es cada color rgb(red, green, blue) por cada pixel, una imagen se puede representar como un array con estos valores.
Las imágenes tendran las dimensiones (64 x 64 x 3), esto es: altura x anchura x profundidad, la profundidad es de 3 por los colores rgb.
training_paths = ["training_images/tesla_model_3/", "training_images/tesla_model_s/", "training_images/tesla_model_x/"]
validation_paths = ["validation_images/tesla_model_3/", "validation_images/tesla_model_s/", "validation_images/tesla_model_x/"]
X_train, y_train = load_images(training_paths)
X_val, y_val = load_images(validation_paths)
Ejecutamos la función para cargar las imágenes indicandole las rutas de cada set de datos, de esta manera obtenemos X_train, y_train y X_train, y_val
X_train tendra las dimensiones (356, 64, 64, 3) ya que en esta variable estan guardadas las 356 imágenes del set de entrenamiento, cada imagen con su respectiva dimensión (64, 64, 3). Si imprimimos una imagen de esta variable veríamos algo parecido a lo siguiente:
[[ 43., 45., 34.],
[ 57., 58., 44.],
[ 63., 65., 51.],
[ 79., 76., 45.],
[ 88., 80., 61.],
[ 63., 63., 55.]]
Es difícil imprimirla completa ya que contiene muchos valores.
La función load_images aparte de cargar las imágenes también crea una variable y que contiene las clases a la cual pertenece cada imagen, el model_3 tiene la clase 0, el model_s tiene la clase 1 y el model_x tiene la clase 2. Es importante que los indices de ambas variables coincidan si en X[89] hay una imagen de un tesla model_s, la variable y[89] tiene que tener el valor 1.
Ya que tenemos las variables del set de entrenamiento y del set de validación toca convertiras a arrays de numpy
X_train = np.array(X_train)
X_val = np.array(X_val)
y_train = np.array(y_train)
y_val = np.array(y_val)
Esto se hace ya que los arrays de numpy tienen mas funciones y son mejores que los arrays normales de python.
con numpy podemos imprimir las dimensiones de cada variable:
X_train.shape, X_val.shape
((356, 64, 64, 3), (90, 64, 64, 3))
y_train.shape, y_val.shape
((356,), (90,))
Ahora toca normalizar las imágenes, como mencione cada array X tiene valores entre 0 y 255 representando el valor de los pixeles de cada imagen, esto quiere decir que un pixel puede tener un valor de 12 y otro pixel puede tener un valor de 243, como podemos notar existe una diferencia muy grande entre estos dos pixels y esa diferencia afecta a la red neuronal, recordemos que una red neuronal usa pesos W que se multiplican con los valores de los datos X, valores muy grandes afectan a esta multiplicación. Lo que haremos es cambiar las distancias de [0, 255] a [0, 1], de esta manera las diferencias entre pixeles son más razonables, Esto se logra con dos líneas de código:
X_train = X_train.astype('float32') / 255
X_val = X_val.astype('float32') / 255
Así de fácil tenemos las imágenes normalizadas.
Como ultimo paso toca modificar las dimensiones de las variables X y y, empecemos por y.
Actualmente y es un array parecido al siguiente:
y = [0, 0, 0, 0, 1, 1, 1, 1, 2, 2, 2, 2]
Contiene las clases de las imágenes en el mismo orden que las imágenes aparecen en X, la red neuronal necesita un formato diferente para entender esta variable, keras tiene una función que resuelve este problema:
y_train = to_categorical(y_train)
y_val = to_categorical(y_val)
to_categorical convierte a la variable y en un array parecido al siguiente:
y = [[1., 0., 0.],
[1., 0., 0.],
[1., 0., 0.],
[0., 1., 0.],
[0., 1., 0.],
[0., 1., 0.],
[0., 0., 1.],
[0., 0., 1.],
[0., 0., 1.],
[0., 0., 1.]]
En lugar de representar la clase con un numero (0, 1, 2) ahora se representa con una posición, cada numero que aparecía en y es un array de tipo [0, 0, 1], si el numero 1 aparece en la primera posición del array [1, 0, 0] esto significa que la imagen pertenece a la primera clase, si aparece en la segunda posición [0 , 1, 0] pertenece a la segunda clase y por supuesto si aparece en la tercera posición pertenece a la tercera clase [0, 0, 1]. También cambian las dimensiones de y:
y_train.shape, y_val.shape
(356, 3), (90, 3))
Es el turno de las variables X, en este caso tendremos que cambiar las dimensiones de las variables, una red neuronal como la que vamos a construir espera recibir un array de dimensiones (m, c), donde m es el numero de datos y c el numero de caracteristicas, recordemos que el numero de caracteristicas es igual al numero de neuronas o nodos que tendra la primera capa de la red neuronal (capa de entrada), para lograr esto necesitamos multiplicar la altura por la anchura y despues por la profundidad
second_shape = 64 * 64 * 3
De esta manera combinamos las caracteristicas que estan en 3 dimensiones en una sola dimensión, el resultado son 12288 nodos.
X_train = X_train.reshape(X_train.shape[0], second_shape)
X_val = X_val.reshape(X_val.shape[0], second_shape)
Gracias a numpy podemos hacer esto de una manera fácil y ahora las variables X tienen dimensiones diferentes:
X_train.shape, X_val.shape
((356, 12288), (90, 12288))
Con todo este proceso ya tenemos los datos listos para usar en la red neuronal.
Creando la red neuronal
El siguiente paso es crear el modelo con ayuda de keras, nuestro modelo tendra dos capas ocultas aparte de la capa de entrada y la capa de salida:
model = Sequential()
model.add(Dense(units=64, input_shape=(12288,)))
model.add(Activation('relu'))
model.add(Dense(units=32))
model.add(Activation('relu'))
model.add(Dense(units=3, activation="softmax"))
Con estas simples líneas de código ya tenemos un modelo listo para el proceso de entrenamiento, pero antes hay que explicar como se construye este modelo.
model = Sequential()
Esta línea indica que el modelo tendra varias capas secuenciales, también define la variable modelo a la cual le agregaremos las capas.
model.add(Dense(units=64, input_shape=(12288,)))
model.add(Activation('relu'))
En dos líneas de código se resume la creación de la capa de entrada y la primera capa oculta. Dense() crea una capa con el numero de neuronas que se le indique, en este caso 64, input_shape indica el numero de neuronas que tendra la capa de entrada, Activation() indica que función de activación usara la capa. En resumen input_shape crea la capa de entrada, Dense() crea la primera cada oculta y Activation() agrega la función de activación a cada neurona de la capa oculta.
Ya que tenemos la capa de entrada y la primera capa oculta pasaremos a crear la segunda capa oculta
model.add(Dense(units=32))
model.add(Activation('relu'))
Esta capa tendra 32 neuronas y la función de activación relu, por ultimo queda crear la capa de salida:
model.add(Dense(units=3, activation="softmax"))
Indicamos que la capa de salida tenga 3 neuronas, una neurona para cada clase y que use la función de activación softmax esta función se usa cuando se tiene un problema de clasificación multiple. Existen diferentes sintaxis para crear un modelo con keras, unas son más explicitas, pueden buscar en la documentación para encontrar otro tipo de sintaxis.
Como podemos notar la creación es muy sencilla, los pesos W y el parametro b se definen internamente, al igual que otros procesos que se tendrían que hacer manualmente si no estuvieramos usando keras.
Pasaremos a definir los parametros de la red neuronal:
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
Con esta función le indicamos a la red neuronal que optimizador y que función de perdida usar, en este caso usaremos el optimizador Adam ya que siempre da buenos resultados y como función de perdida usaremos categorical crossentropy, esta función de perdida es la misma que usamos en el modelo de regresión logistica pero con pequeños cambios para que funcione en problemas de clasificación multiple. El ultimo parametro que indicamos es metrics, queremos saber cual es la exactitud del modelo, que porcentaje de imágenes pudo clasificar correctamente. Recordemos que todas estos parametros son llamados hiperparametros (hyperparameters) y que de estos depende que el modelo sea bueno o malo.
El ultimo paso es decirle al modelo que empiece el proceso de entrenamiento y eso lo hacemos con el siguiente código:
epochs = 10
batch_size = 32
model_train = model.fit(X_train, y_train, batch_size=batch_size, epochs=epochs, verbose=1, validation_data=(X_val, y_val))
Esta función necesita las variables de entrenamiento y las variables de validación, también indicamos las epocas que la red entrenara y el tamaño en el cual se dividiran los datos en cada ciclo.
Despues de que la red neuronal termine el entrenamiento podemos graficar el progreso de cada epoca:
def plot_loss_and_accuracy(model_train):
accuracy = model_train.history['acc']
val_accuracy = model_train.history['val_acc']
loss = model_train.history['loss']
val_loss = model_train.history['val_loss']
epochs = range(len(accuracy))
plt.plot(epochs, accuracy, 'b', label='Training accuracy')
plt.plot(epochs, val_accuracy, 'r', label='Validation accuracy')
plt.ylim(ymin=0)
plt.ylim(ymax=1)
plt.xlabel('Epochs ', fontsize=16)
plt.ylabel('Accuracity', fontsize=16)
plt.title('Training and validation accuracy', fontsize = 20)
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'b', label='Training loss')
plt.plot(epochs, val_loss, 'r', label='Validation loss')
plt.xlabel('Epochs ',fontsize=16)
plt.ylabel('Loss',fontsize=16)
plt.title('Training and validation loss', fontsize= 20)
plt.legend()
plt.show()
Necesitamos esta función para graficar el progreso, usamos la librería matplotlib para lograrlo.
Ahora solo le pasamos el resultado del modelo como parametro:
plot_loss_and_accuracy(model_train)
Y tendremos dos graficas:
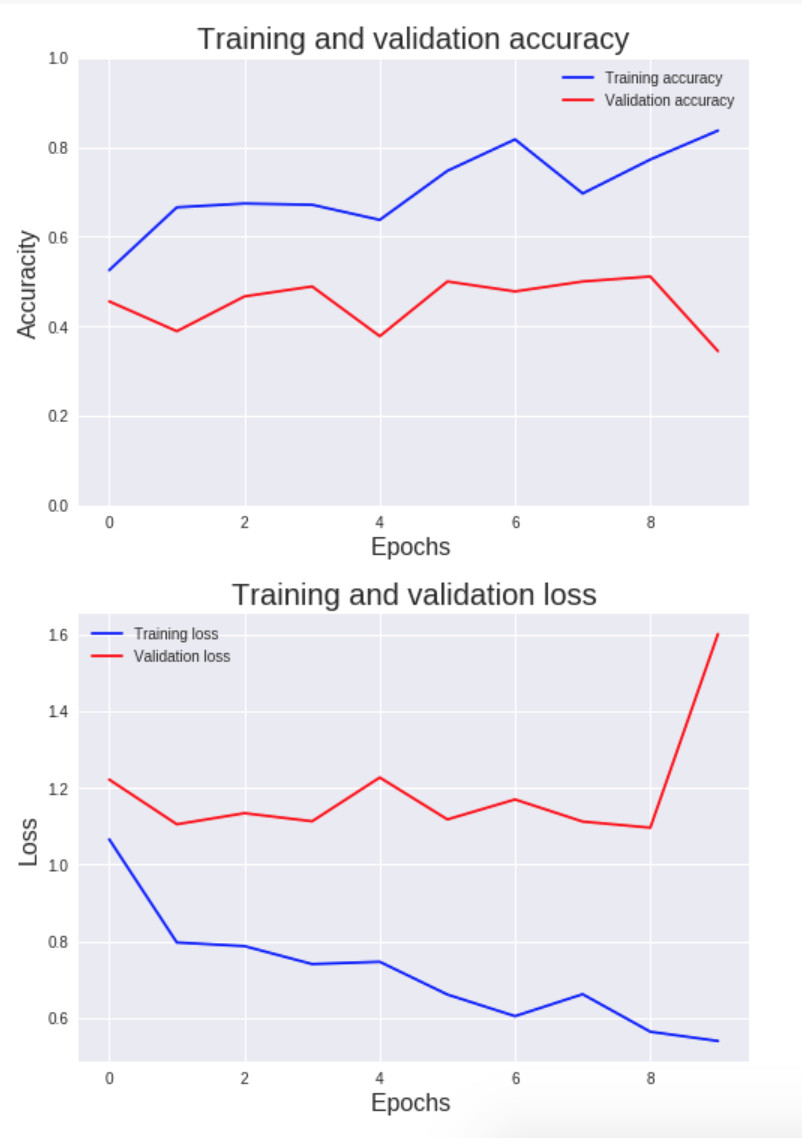
Podemos ver como cambia el valor de la función de costo y la exactitud de la red nueronal por cada ciclo.
también podemos obtener los valores finales para cada set de datos
validation_acc = model_train.history['val_acc'][-1] * 100
training_acc = model_train.history['acc'][-1] * 100
print("Validation accuracy: {}%\nTraining Accuracy: {}%".format(validation_acc, training_acc))
Validation accuracy: 34.44444470935398%
Training Accuracy: 83.70786516853933%
Los resultados que obtuve pueden ser muy diferentes cada vez que la red neuronal pasa por el proceso de entrenamiento, esto se debe a que los valores de los pesos W son asignados aleatoriamente cuando se crea un modelo, este comportamiento aleatorio es importante ya que no podríamos tener pesos con valores iguales, si esto pasara todas las neuronas aprenderían el mismo patron sobre los datos.
Con estos resultados podemos estar seguros de que la red neuronal tiene un sobre ajuste (overfitting), la diferencia entre la exactitud del set de validación y el set de entrenamiento es muy grande. El mayor problema en este modelo son las pocas imágenes que tenemos, son 356 imágenes de entrenamiento y un aproximado de 120 imágenes por cada clase, son muy pocas para obtener un buen resultado, existen varios procesos para mejorar los resultados de una red neuronal, uno de ellos se llama aumento de datos (data augmentation), la idea de este proceso es modificar las imágenes que tenemos para aumentar la cantidad total, podemos voltear horizontalmente una imagen, hacer zoom en una sección, agregar efectos, si tenemos 300 imágenes y cada una de ellas la volteamos horizontalmente, ya tenemos 600 imágenes. Keras tiene funciónes para lograr esto pero necesitamos otro tipo de red neuronal, una que se especializa en reconocer imágenes y que tiene mejores resultados en esta tarea que las redes neuronales normales, este tipo de red neuronal se llama convolucional, en Ingles convolutional neural network (CNN) y la veremos en otro tutorial, por ahora trataremos de mejorar la red actual y aprenderemos como usar esta red para clasificar imágenes que descarguemos de internet.
Mejorando la red neuronal
Cambiaremos algunos hiperparametros del modelo para evitar el sobre ajuste:
second_model = Sequential()
second_model.add(Dense(units=16, input_shape=(12288,)))
second_model.add(Activation('relu'))
second_model.add(Dense(units=32))
second_model.add(Activation('relu'))
second_model.add(Dense(units=64))
second_model.add(Activation('relu'))
second_model.add(Dense(units=3, activation="softmax"))
Cambiamos el numero de neuronas de la primera capa y agregamos una tercera capa con 64 neuronas.
Si entrenamos esta nueva red neuronal:
second_model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
second_model_train = second_model.fit(X_train, y_train, batch_size=batch_size, epochs=epochs, verbose=1, validation_data=(X_val, y_val))
graficamos el progreso:
plot_loss_and_accuracy(second_model_train)
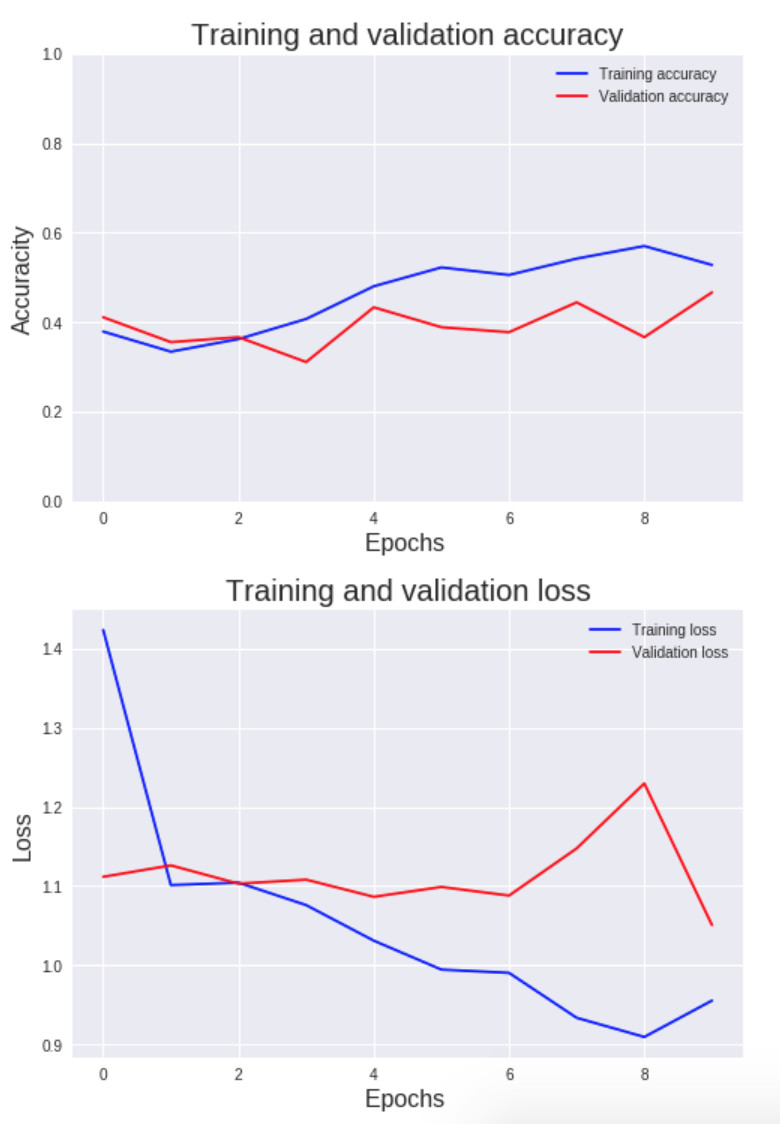
y vemos los resultados finales:
validation_acc = second_model_train.history['val_acc'][-1] * 100
training_acc = second_model_train.history['acc'][-1] * 100
print("Validation accuracy: {}%\nTraining Accuracy: {}%".format(validation_acc, training_acc))
Validation accuracy: 46.66666673289405%
Training Accuracy: 52.80898876404494%
Como podemos notar esta red neuronal tiene valores más equilibrados que la anterior, pero sigue siendo insuficiente para reconocer cada clase.
Podemos usar el modelo para predecir nuevos datos, primero necesitaremos tres nuevas imágenes, una para cada clase:
{kind=link}
{kind=link}
{kind=link}
Una vez descargadas tenemos que cargarlas con python
X = []
image = load_img("./Tesla-Model-3-4-720x550.jpg", target_size=(img_height, img_width))
image_array = img_to_array(image)
X.append(image_array)
image = load_img("./109102_source-2.jpg", target_size=(img_height, img_width))
image_array = img_to_array(image)
X.append(image_array)
image = load_img("./2017_Tesla_Model_X_100D_Front.jpg", target_size=(img_height, img_width))
image_array = img_to_array(image)
X.append(image_array)
X_test = np.array(X)
Normalizar los datos y cambiar las dimensiones
X_test = X_test.astype('float32') / 255
X_test = X_test.reshape(X_test.shape[0], second_shape)
Ahora con la función predict de keras podemos saber que clase le asignara a cada imagen la red neuronal
y_pred = second_model.predict(X_test, batch_size=None, verbose=1, steps=None)
Esta función devuelve un arreglo con las probabilidades de cada clase para cada imagen, la más alta es la que tomaremos como predicción:
y_pred = [[0.22741655, 0.4156091 , 0.35697436],
[0.583717 , 0.3267301 , 0.08955295],
[0.35106906, 0.5099873 , 0.13894367]]
np.argmax(y_pred, axis=1)
array([1, 0, 1])
Las imágenes estan ordenadas por clases: [0, 1, 2], esto significa que la red neuronal no pudo predecir ninguna clase correctamente, esto es normal ya que la red neuronal que construimos no es la mejor, hay ciertas tecnicas que podríamos implementar, como Dropout y batch normalization. En otro tutorial veremos como funcionan estas dos tecnicas que son muy importantes para despues finalizar con una red neuronal convolucional.